
Learning Air Pollution with LSTM RNN
🔍 Why Air Pollution Prediction Matters
Air pollution is a silent but deadly problem affecting millions worldwide. It’s not just about smog-filled skies—it’s about the long-term health risks, like lung cancer, that come from prolonged exposure to pollutants like PM2.5. But here’s the catch: air pollution isn’t evenly spread. It varies from place to place and changes over time. To truly understand and combat it, we need accurate ways to predict pollution levels across large areas and over long periods. That’s where our research comes in.
Traditional methods for estimating air pollution rely on simple mathematical models, which often miss hidden factors like weather patterns, traffic, or even human activity. We wanted to do better. Using deep learning, we developed a smarter way to predict air pollution—one that considers both space and time, and even factors we can’t directly measure. The result? A groundbreaking approach that’s more accurate and efficient than ever before.
🛠️ How We Did It: A Deep Learning Approach
Our method is built on a type of deep learning called Bidirectional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM RNN). Sounds complicated, right? Let’s break it down.
Imagine you’re trying to predict tomorrow’s air quality. You’d look at today’s data, but you’d also consider what happened yesterday, last week, or even last year. That’s what our Bi-LSTM RNN does—it “remembers” past data and uses it to make better predictions. But it doesn’t stop there. It also looks ahead, considering future trends, which makes it even more accurate.
We trained our model using real-world data from air quality monitoring stations across Georgia and Florida. Each station provided daily PM2.5 measurements, along with location and time data. Our goal was to estimate pollution levels at any point in the region, even where no monitoring stations existed.
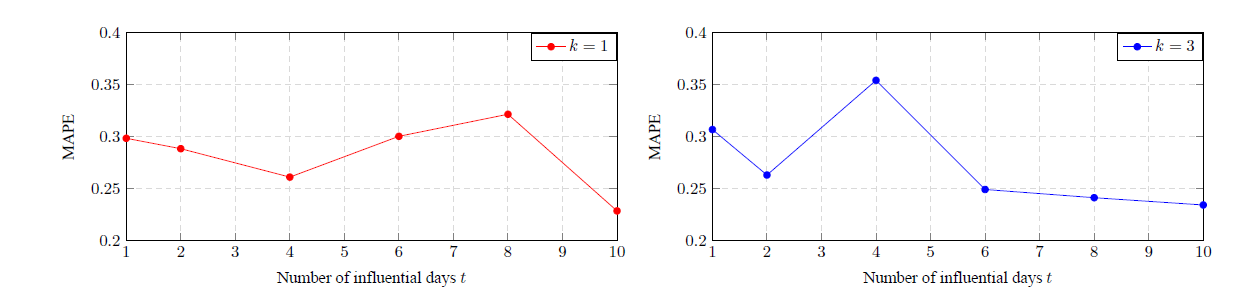
📊 What We Found: Better Predictions with Deep Learning
Our experiments showed that our Bi-LSTM RNN model outperformed traditional methods. Here’s what stood out:
- Neighbors Matter: Pollution levels at nearby locations significantly influence each other. The more neighbors we considered, the more accurate our predictions became (see Figure 1).
- Time Matters: Historical data is crucial. By looking at past pollution levels, our model could predict future trends with greater precision.
- Looking Ahead Helps: Unlike traditional models, our Bi-LSTM RNN also considers future data, which further improved accuracy.
For example, when we compared our Bi-LSTM RNN to a simpler LSTM model, the results were clear: our approach reduced prediction errors by up to 15%.
💡 What This Means for the Future
Our research isn’t just about predicting air pollution—it’s about creating tools that can help policymakers, scientists, and communities take action. For instance, accurate predictions could guide the placement of air quality monitors, inform public health warnings, or even shape urban planning to reduce emissions.
But we’re not stopping here. In the future, we plan to expand our model to include more factors, like temperature, wind speed, and traffic data. We also want to test it on larger datasets, like hourly pollution measurements across the entire U.S. And as the data grows, so will the computational challenges. That’s why we’re exploring ways to make our model faster and more efficient, possibly using advanced computing frameworks.
Ultimately, our goal is to create a tool that’s not just accurate, but also accessible. Because when it comes to air pollution, knowledge is power—and we’re here to share it.