
Predicting Air Pollution in China with Deep Learning
Using Deep Learning to Predict Air Pollution in China: A Data Fusion Approach
🔍 Why Predicting Air Pollution Matters
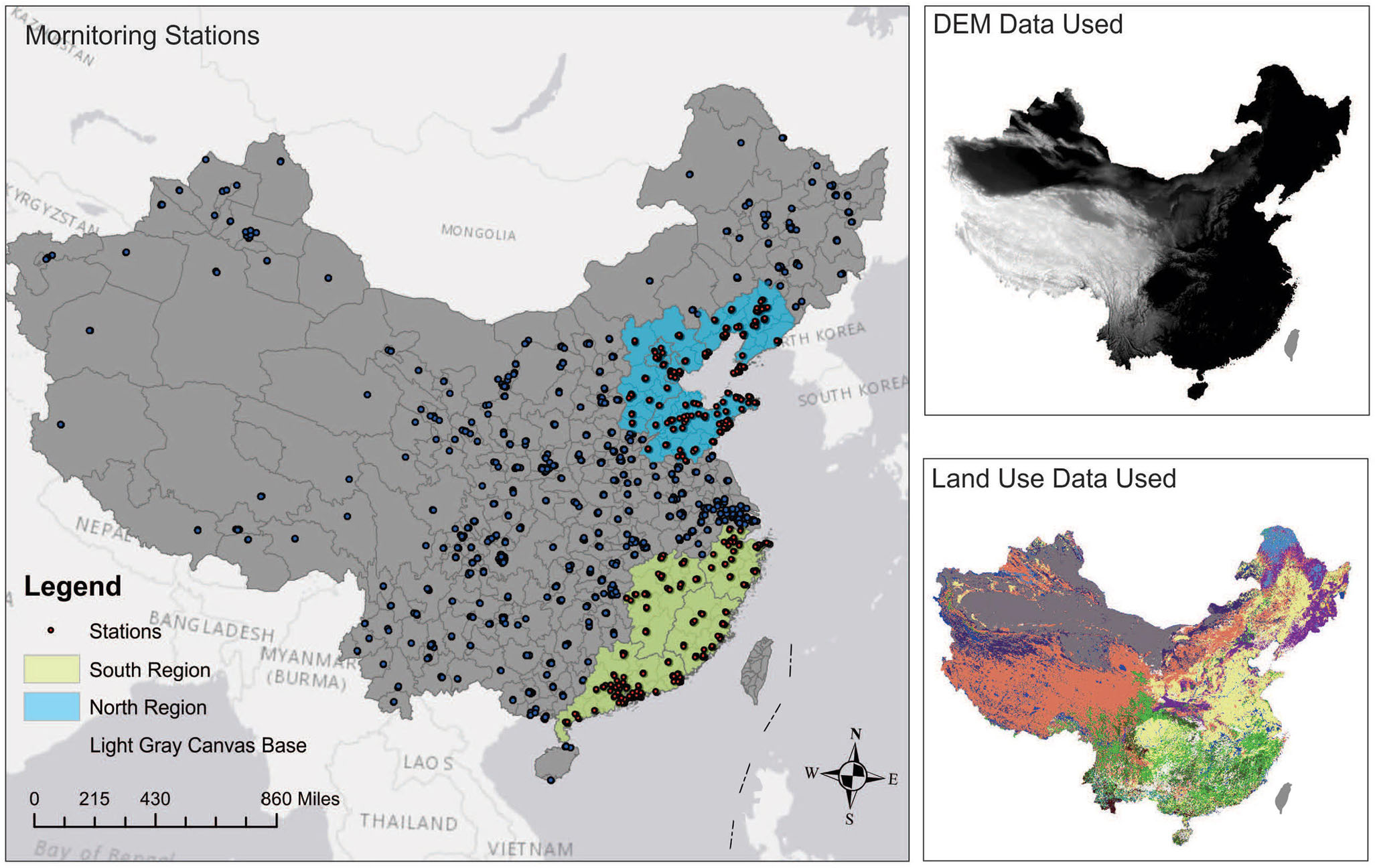
Air pollution, particularly PM2.5 (tiny particles less than 2.5 micrometers in diameter), is a major global health concern. These particles are so small that they can penetrate deep into our lungs, causing serious health issues like lung cancer, cardiovascular diseases, and even strokes. In rapidly urbanizing countries like China, the problem is especially severe. But here's the challenge: while we have air quality monitoring stations, they can't cover every location or provide continuous data. That's where our research comes in.
We set out to develop a deep learning model that could predict PM2.5 levels across both space and time, even in areas without monitoring stations. By combining data from multiple sources—like weather, elevation, and land use—we aimed to create a tool that could help governments and communities make better decisions about air quality management.
🛠️ How We Built the Model
To tackle this problem, we used a Long Short-Term Memory (LSTM) recurrent neural network, a type of deep learning model that’s great at handling time-series data. Think of it like a super-smart memory system that can learn patterns over time. But we didn’t stop there. We also incorporated data fusion, which means we combined multiple types of data to make our predictions more accurate. Here’s what we included:
- PM2.5 data from monitoring stations
- Meteorological data like temperature, wind speed, and precipitation
- Elevation data to account for terrain effects
- Land-use data to understand how different areas (urban, rural, industrial) affect pollution levels
We tested our model in two regions of China: the heavily polluted north (Beijing-Tianjin-Hebei-Shandong-Liaoning) and the relatively cleaner south (Guangdong-Jiangxi-Fujian-Zhejiang). By comparing these regions, we could see how well our model performed in different environments.
📊 What We Found
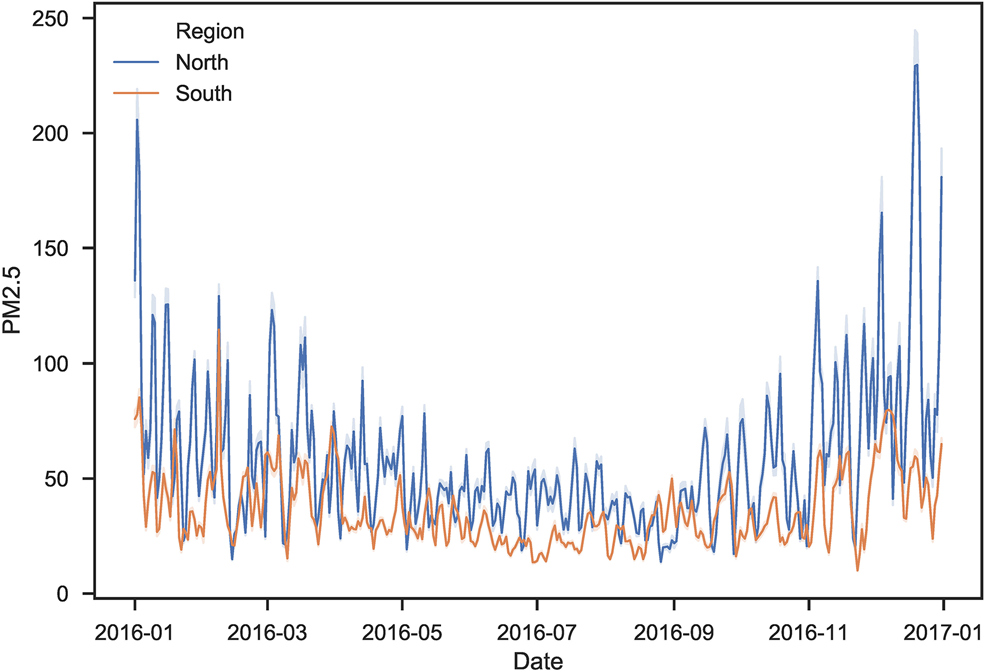
Our results were promising! The LSTM model outperformed traditional machine learning methods, achieving higher accuracy in predicting PM2.5 levels. Here’s a quick breakdown of our findings:
- Meteorological factors like wind and temperature had the biggest impact on improving predictions.
- Land-use and elevation also helped, but their contributions were smaller compared to weather data.
- The model performed consistently well in both the north and south regions, though it was slightly better in the south due to lower pollution variability.
Here’s a snapshot of how our model improved over time:
💡 What This Means for the Future
Our research shows that combining deep learning with data fusion is a powerful way to predict air pollution. But this is just the beginning. Here’s how we see this work evolving:
- Real-time predictions: We’re working on making our model faster and more efficient, so it can provide real-time air quality forecasts.
- Global applications: While we focused on China, our approach can be adapted to other regions facing air pollution challenges.
- Policy impact: By providing accurate predictions, our model can help governments design better policies to reduce pollution and protect public health.
Air pollution is a complex problem, but with tools like this, we’re one step closer to solving it. Stay tuned for more updates as we continue to refine and expand our research!